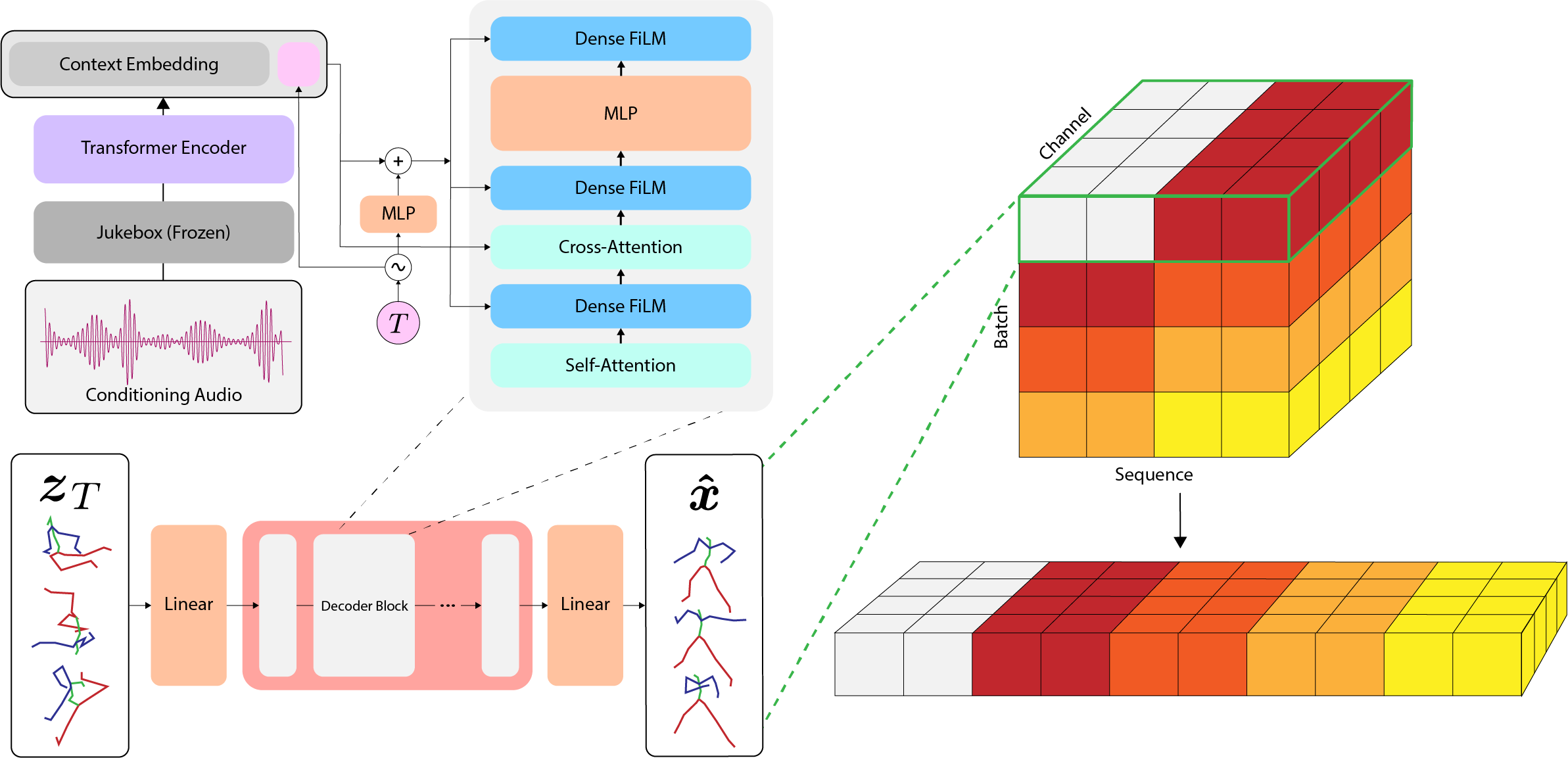
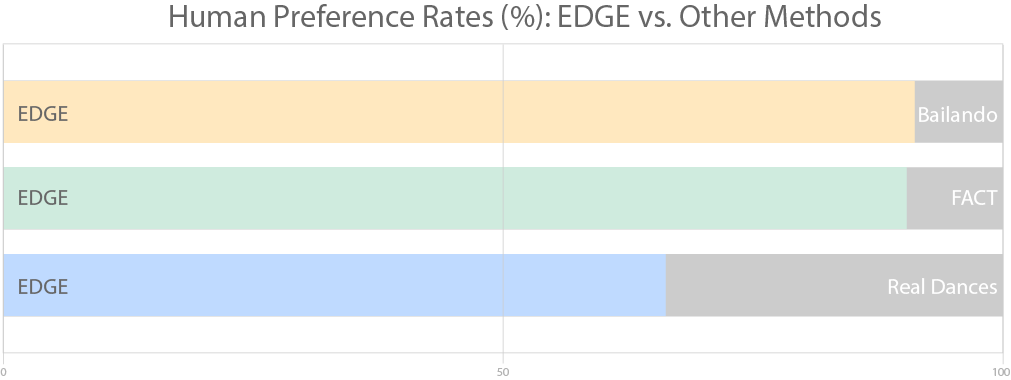
We introduce EDGE, a powerful method for editable dance generation that is capable of creating realistic, physically-plausible dances while remaining faithful to arbitrary input music. EDGE uses a transformer-based diffusion model paired with Jukebox, a strong music feature extractor, and confers powerful editing capabilities well-suited to dance, including joint-wise conditioning, motion in-betweening, and dance continuation. We compare EDGE to recent methods Bailando and FACT, and find that human raters strongly prefer dances generated by EDGE.